分享我参与严选技术工作组的日志平台项目中的时候,在日志收集agent这块遇到的一些问题,深入到每个底层细节和大家谈谈。
日志agent对于使用日志平台的用户来说,是一个黑盒。对于用户来说,agent有些不好的地方:
- agent私底下偷偷摸摸都做了些什么事情呢?(阴暗的)
- agent的设计实现其实有一些dirty、creepy的地方(潮湿的)
所以我觉得日志收集agent对大家来说是一个阴暗潮湿的地底世界:

就让我举起火把,照亮所有dark、dirty、creepy的地方。
背景提要
日志收集我们知道是在宿主服务器通过一个agent来收集日志数据,并且将收集到的数据源源不断的发送到日志平台的下游链路消费。
正是因为日志收集agent是整个日志平台的唯一数据来源,所以日志收集的地位非常重要。一旦日志收集agent出现问题,轻则影响后续链路的报警和查询,重则影响宿主服务器,反客为主,影响更为重要的应用系统。
所以,先来看看我们选型agent的时候有些什么阴暗的地方:
日志收集agent方案
由于日志收集agent的特殊性,我们对于agent的要求优先级由高到低如下:
低耗>稳定>高效>轻量
以此原则,我们逐步推动agent的演进。
日志收集agent初期方案
其实日志平台一开始并没有对比太多其他的agent方案,直接就是使用的flume作为agent。
why?
基于MVP(minimum viable product)原则,日志平台第一版的选项更看重能快速上线、快速试错、快速验证。而且严选这边其实之前就存在一套日志收集系统是用的flume,我们决定先复用flume,再对其定制。然后其实还有一个更重要的原因:为了兼容一些历史问题(例如收集的日志要写到北京kafka的情况),我一开始不得不沿用flume作为agent的方案。
then?

以为我们agent就此受困于历史的漩涡中束手束脚,止步不前?不存在的,我们同步调研了filebeat的方案。来看看我们对filebeat的调研工作:
filebeat作为日志收集agent
先来看下2者之间的对比:
| filebeat | flume | |
|---|---|---|
| 语言 | go | java |
| 包大小 | <10m | >68m |
| 额外依赖 | 无 | 根据source与sink的不同可能需要额外的依赖包 |
| 配置复杂度 | 中 | 较高 |
| 性能 | 高 | 低 |
| 资源占用 | 低 | 高 |
| 扩展性 | 低 | 高 |
| 可靠性 | 高(at-least-once) | 高(at-least-once) |
| 限流 | 自带,背压敏感协议 | 自定义开发扩展的一个Interceptor |
| 负载均衡 | 内置 | 内置 |
| 输入源 | 内置了几个 | 支持多样的输入源,方便的自定义扩展输入源 |
| 输出源 | 内置了几个 | 内置比较丰富,方便的扩展 |
权衡优劣后,我更倾向于选择filebeat作为日志收集的agent,原因如下:
- 我们对于agent的需求是低耗、稳定、高效、轻量。扩展性显得并不那么重要,功能丰富与稳定性,我更倾向于后者
- 对于输入源,我们的场景也正好只是基于文件的日志数据收集,filebeat已经满足我们的需求场景
- 对于输出源,filebeat需要定制开发,支持http/grpc,有一定开发成本,但是完全可以接受
- 目前flume-agent的方案,日志切分是在flink任务中,导致后续架构链路冗长。使用filebeat完全可以把切分的工作放在agent端来简化架构链路,这对于后续日志平台的运维也大有裨益
同时,我们做了filebeat的压测,压测数据如下:
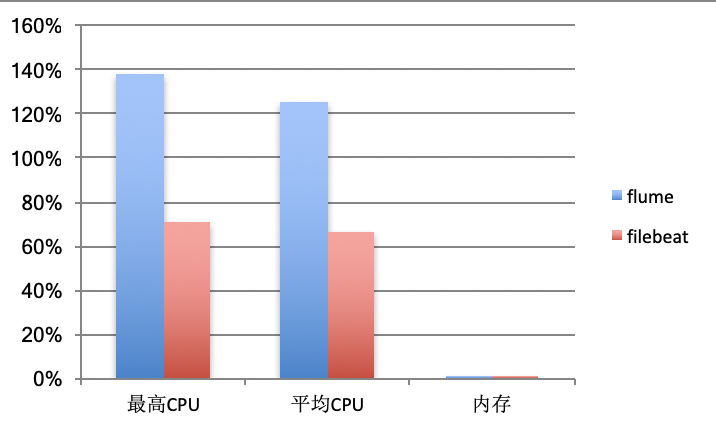
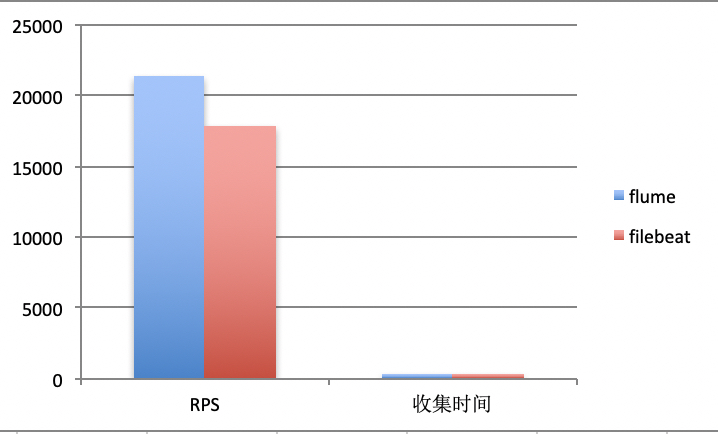
其结果让我们震惊,在内存占用很低的情况下(3%以下),最高cpu占用只有70%,flume(平均145%)的一半不到。这使我们以后的agent方案逐渐向filebeat倾斜。
好了,是时候来点干货了,我们来看看日志收集都有哪些问题?哪些creepy的设计?
如何发现日志文件
agent如何发现哪些日志文件是要被收集的呢?主要有如下几种方式:
- 用户配置
- 优点:简单高效。用户直接把需要采集的日志文件给配进来,可以说是最简单高效的办法。
- 缺点:日志文件很可能是会按天滚动(rotate)的,提前配置肯定覆盖不了后面新创建的日志文件。
- 正则匹配(例如:
access_log\.\d{4}-\d{2}-\d{2}\.\d{2})- 优点:灵活。能够很好的覆盖到各种滚动新建的日志文件
- 缺点:正则由用户输入,效率堪忧,一旦发生大量回溯,很可能cpu100%。这也是我们最不希望发生在agent端的问题
- 占位符匹配(例如:
access_log.yyyy-MM-dd.log)- 优点:灵活高效。即能很好的匹配新创建的日志文件,agent端的匹配效率也非常高
- 缺点:对于一些奇葩命名滚动规则的日志文件不太好适应
日志平台使用的是占位符匹配的方式,但是后端其实是兼容正则匹配的,这是出于兼容历史的原因,后面将逐步去掉正则的匹配的方式。
解决了如何发现文件后,紧接着就会遇到另一个问题:
如何发现新创建的文件
直觉做法肯定是轮询目录中的日志文件,显然这不是个完美的方案。因为轮询的周期太长会导致不够实时,太短又会耗CPU。
这真是一个艰难的trade-off
我们来对比下flume(以下所说的flume都是我们基于flume改造定制的yanxuan-flume)和filebeat的做法:
yanxuan-flume:轮询
flume目前是每隔500ms去轮询查找是否有新的日志文件,基本上就我们前面提到的”直觉做法”。实现简单,但是我们很难衡量这个
500ms是否是一个合适合理的值。fliebeat:OS内核指令+轮询
filebeat的方案就完善优雅很多。依赖OS内核提供的高效指令,分别是:
- linux:inotify
- macos:fsevents
- windows:ReadDirectoryChangesW
来通知是否有新文件,并且辅助一个周期相对较长的轮询来避免内核指令的bug(具体参考其man page)),取长补短,低耗与高效兼得
又多了一个使用filebeat的理由
好了,现在我们已经清楚如何发现文件了,那么问题又来了,我们如何知道这个文件是否已经收集过了?如果没有收集完,应该从什么位置开始接着收集?
如何标识一个日志文件收集的位置
一般是用一个文件(这里我们称之为点位文件)来记录收集的文件名(包含文件路径)与收集位置(偏移量)的对应关系,key就是文件名称,value就是偏移量。记录到文件的好处是,在机器宕掉后修复,我们还能从文件中恢复出上次采集的位置来继续收集。如下图所示:
那么,点位文件存在什么问题呢?点位文件使用日志文件名称作为key,但是一个日志文件的名称是有可能被更改的,当文件被改名后,由于点位文件中查询不到对应的采集位置,agent会认为是一个全新的日志文件而重头重新收集。所以用文件名称不能识别一个文件。那么问题又来了:
如何识别一个文件
如何识别一个文件,最简单的就是根据文件路径+文件名称。但是我们上面说了,文件很可能被改名。每个文件其实都有个inode属性(可以使用命令stat test.log查看),这个inode由OS保证同一个device下inode唯一。所以自然而然的我们就会想到用device+inode来唯一确定一个文件。然而inode是会重新分配的,即当我们删除一个文件后,其inode是会被重复利用,分配给新创建的文件。
举个常见例子:假如日志文件配置为保留30天,那30天以前的日志文件是会被自动删除的。当删除30天前的日志文件,其inode正好分配给当天新创建的日志文件,那当天的日志是不会被收集的,因为在点位文件中记录了其采集偏移量。
我们来看看flume和filebeat是怎么做的:
yanxuan-flume:device+inode+首行内容MD5
优点:无需用户干预,能保证唯一识别一个文件
缺点:需要打开文件读取文件内容,而且首行内容MD5还是太暴力了,因为首行很可能是一个超长日志,再加上MD5,不仅耗CPU,而且判断效率有点低。
可以考虑读取首行N个字节的内容md5,但是N到底取多大呢? 越大相同的概率越小,效率越低。反过来,N越小重复的概率越大,效率越高。这又是一个艰难的trade-off啊
filebeat:device+inode
优点:判断效率高。无需打开文件读取内容即可判断
缺点:可能会误判
filebeat提供了一个配置选项来决定何时删除点位文件中的记录:
clean_inactive:72h表示清除72h不活跃的文件对应的点位文件中的记录。基本上我们的文件都是每天(24h)滚动(rotated)的,那前一天的日志文件是不会写入的,所以设置clean_inactive:72h是合理的。那为什么不在日志文件被删除后直接删除点位文件中对应的记录呢?因为假如我们的日志文件在一个共享的存储分区中,当这个分区消失了一会(接触不良等情况)又重新出现后,里面的所有日志文件都会重头开始重新收集,因为他们的收集状态已经从点位文件中删除了。
我觉得这是一个合理的”甩锅”给使用者的配置选项。
解决了如何标识文件,如何标识采集状态,那如何判断一个日志文件采集完了呢?采集到末尾返回EOF的时候就算采集完了,可是当采集速度大于日志生产速度的时候,很可能我们采集到末尾返回EOF后,又有新的内容写入。所以,问题就变成:
如何知道文件内容更新了
最简单通用的方案就是轮询要采集的文件,发现文件内容有更新就采集,采集完成后再触发下一次的轮询,既简单又通用。
那具体是轮询什么呢?
- yanxuan-flume:按照文件的修改时间排序,轮询文件内容,尝试收集,如果返回是EOF则继续下一份文件
- filebeat:按照文件的修改时间排序,轮询文件的stat状态,修改时间大于点位文件中记录的时间,则打开文件收集,返回EOF则继续下一份文件
相比flume,filebeat又做了一个小优化,每次不会直接就打开文件,而是先比较文件的修改时间再决定是否打开文件进行收集。
不得不感叹,魔鬼在细节!低耗和高效如何兼得,filebeat处处都是细节
好了,知道该什么时候收集了,那我们具体收集的时候会遇到什么问题呢?
如何收集多行日志
目前的agent默认都是单行收集的,即遇到换行符就认为是一条全新的日志。可是很多情况下,我们的一条日志是多行的,比如异常堆栈、格式化后的sql&json等。
那如何判断那几行是属于同一条日志呢?
yanxuan-flume:flume原生是不支持的,我们自己写了个插件,通过配置一条日志的开头字符S来判断。假如一行日志的开头不是S,则认为是和上一行属于同一条日志
filebeat:支持flume类似的方式,同时提供了配置项
negate:true 或 false;默认是false,匹配开头字符S的行合并到上一行;true,不匹配S的行合并到上一行。能够覆盖更多的多行日志场景。当然还有其他相关配置来兜底合并行可能带来的问题,例如一次最多合并几行和合并行的超时时间来防止可能的内存溢出与卡死
万无一失了吗?想想多行日志的最后一行按照以上的逻辑可以正常收集吗?例如下图所示:
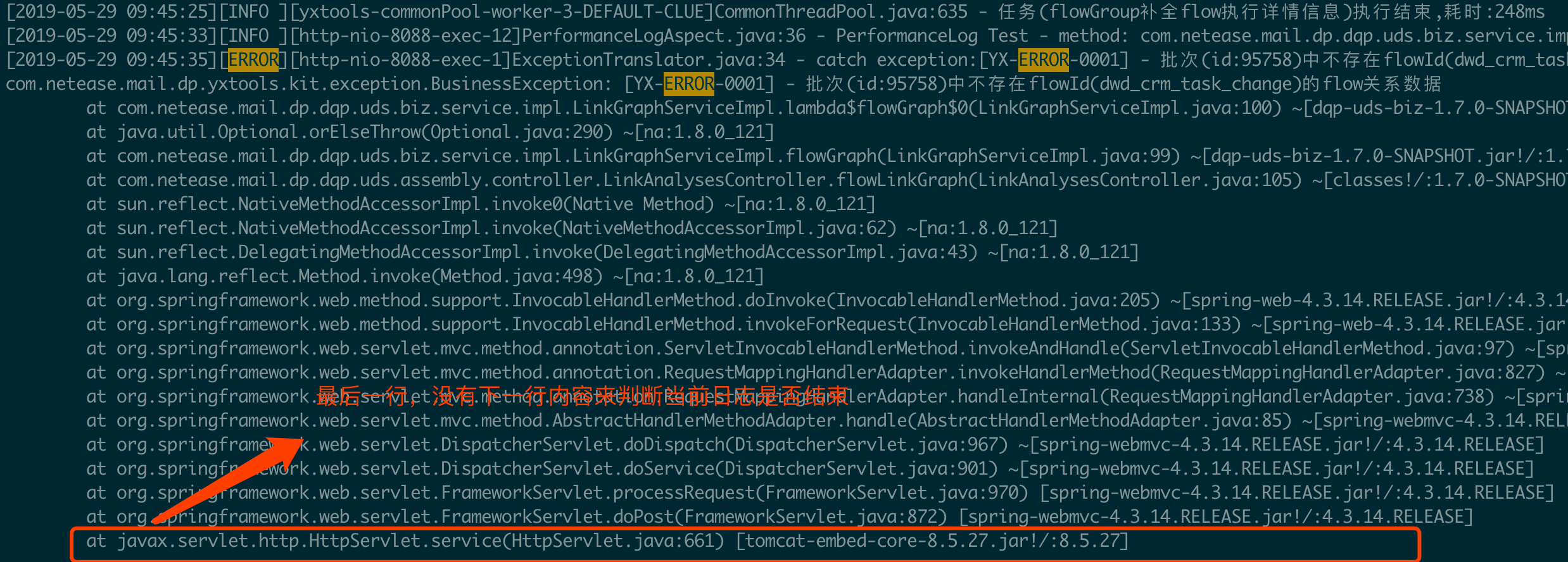
如何处理多行日志的最后一行
当多行日志收集遇到最后一行怎么收集呢?还是来比较下flume和filebeat的做法:
- yanxuan-flume:遇到EOF即认为是这条多行日志收集完了。这有个问题就是,很可能这条多行日志还没有写完,就被收集发送出去了。而且当收集速度大于日志写入速度的时候或者异步打印日志的时候,又很容易发生这种情况
- filebeat:遇到EOF会回退之前读取的内容,然后一直持有这个文件句柄(直到超时),直到新一行日志写入,根据新一行日志的行首字符匹配来判断是否当前行的日志结束。所以filebeat的存在的问题是很可能最后一行永远不会被收集
目前业界貌似没有太好的办法来完美解决这个问题。个人觉得基于filebeat的多行合并的超时时间配置选项能够很大程度缓解这个问题,因为多行日志往往也是一次性写入的,超过一定时间写入的往往都是一条全新的日志。
