本文根据官网文档及对公司日志平台es升级调优经验分享,如有错误,欢迎斧正。
主题
- 环境调优 - 磨刀不误砍柴工
- 概念普及 - 步调一致
- 如何合理高效查询 - 查询说明
- 如果合理高效的写入(另外写)
环境调优是先决条件,应对查询和写入都有帮助。重点分享查询,因为目前业务没有高频写入的场景
环境调优
注意:配置只针对centos,其他系统未做测试。
设置elasticsearch的jvm内存
编辑jvm.options,添加一下内容:
|
|
注意:具体大小应当<=系统内存的一半,建议直接设置为系统内存的一半
禁用swap交换空间
大多数操作系统试图尽可能多地为文件系统缓存使用内存,并急切地交换掉未使用的应用程序内存。这可能会导致JVM堆的部分甚至将其可执行页被交换到磁盘。
交换对于性能、节点稳定性是非常不利的,应该不惜一切代价避免。它可能导致垃圾收集持续数分钟而不是毫秒,并可能导致节点响应缓慢,甚至可能断开与群集的连接。
禁用虚拟内存,并让jvm锁定内存:
- swapoff -a
- 编辑文件
/etc/fstab,注释掉所有包含swap的行 - 编辑文件
elasticsearch.yml,添加配置bootstrap.memory_lock: true
验证是否锁定内存成功:
|
|
调整文件句柄数量
Lucene 使用了 大量的 文件。 同时,Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字(注:sockets)。所有这一切都需要足够的文件描述符
先临时设置允许的文件句柄数量:
- sudo su
- ulimit -n 65536
- su elasticsearch
以上确保在当前session生效,再永久设置:
编辑/etc/security/limits.conf,添加一行,内容为elasticsearch - nofile 65536
验证是否设置成功:
|
|
调整文件映射数量
Elasticsearch 对各种文件混合使用了 NioFs( 注:非阻塞文件系统)和 MMapFs ( 注:内存映射文件系统)。请确保你配置的最大映射数量,以便有足够的虚拟内存可用于 mmapped 文件
先临时设置:
|
|
再永久修改:
编辑/etc/sysctl.conf,添加vm.max_map_count=262144
调整允许的线程数量
|
|
概念普及
index(名词):索引 ≈ mysql中的库(database)
type:类型 ≈ mysql中的表
document:文档 ≈ mysql中的一行数据
share:分片 ≈ mysql中的数据分表
replicas:副本,即数据分片备份
index(动词):为文档创建索引
分片与副本
一个索引应设置几个分片,几个副本才合理?
副本
分片副本用来应对不断攀升的吞吐量以及确保数据的安全性.副本可以动态改变,默认为1份副本,比较合理。
当查询吞吐量跟不上时,可以考虑增加副本数量。
分片
分片无法动态指定,只能在创建index的时候指定。(why?)
但是默认设置5个分片,这通常来说属于过度分配,这是作者考虑到数据迁移成本的权衡。
原则就是最小分片。多个分片对于查询和写入都有额外消耗。
什么时候该违反这个原则?
- 由于单个分片有数量上限(Integer.MAX_VALUE=2147483647)
- 单机资源限制,如单个分片所占用磁盘过大
- 为了吞吐量和单机热点,大数量写入被分到不同集群中的不同分片中,避免频繁写入占用过多系统资源,从这点看,也能加快查询吞吐量
所以,根据“经验法则”,小集群时合理的分片数量==节点数量
如何合理高效查询
elasticsearch的查询可以在主分片和副本分片查询
查询流程
根据_id查询流程图:
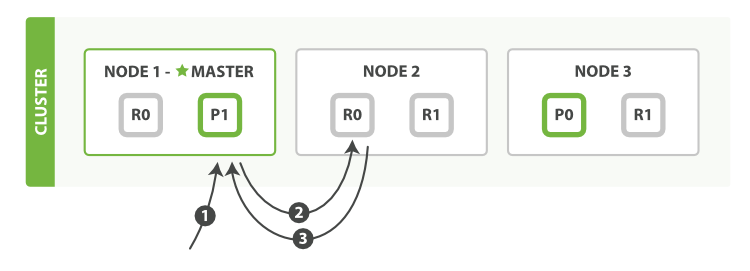
以下是从主分片或者副本分片检索文档的步骤顺序:
- 客户端向
Node 1发送获取请求 - 节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到
Node 2 Node 2将文档返回给Node 1,然后将文档返回给客户端
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡
如果查询有全文检索和聚合操作(例如排序),elasticsearch需要每个分片都执行查询,并把结果返回给协调节点,由协调节点进行聚合操作后再返回被客户端。
如何路由一个文档到一个分片
根据以下公式:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数
这也是为何副本数量能够动态修改,而分片数量需要创建索引时就确定好 – 因为如果分片数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了
查询原理
- 倒排索引
- 精确值 & 全文域
- query查询 & filter查询
倒排索引

倒排索引为何叫倒排索引?
一个普通的数据库中,一般是以文档ID作为索引,以文档内容作为记录。
而倒排索引指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。刚好倒过来。
思考:有没有更好快的数据结构?如果有,为何不用?
精确值 & 全文域
elasticsearch中数据类型大致可以分为2类:精确值和全文域
精确值如它们听起来那样精确。例如日期或者用户ID,但字符串也可以表示精确值,例如用户名或邮箱地址。对于精确值来讲,Foo和foo是不同的,2014和2014-09-15也是不同的
精确值很容易查询。结果是明确的:要么匹配查询,要么不匹配
全文通常是指非结构化的数据,但这里有一个误解:自然语言是高度结构化的。问题在于自然语言的规则是复杂的,导致计算机难以正确解析
查询全文数据要微妙的多。我们问的不只是“这个文档匹配查询吗”,而是“该文档匹配查询的程度有多大?”换句话说,该文档与给定查询的相关性如何?
我们很少对全文类型的域做精确匹配。相反,我们希望在文本类型的域中搜索。不仅如此,我们还希望搜索能够理解我们的意图:
- 搜索 UK ,会返回包含 United Kindom 的文档。
- 搜索 jump ,会匹配 jumped , jumps , jumping ,甚至是 leap 。
- 搜索 johnny walker 会匹配 Johnnie Walker , johnnie depp 应该匹配 Johnny Depp
- fox news hunting 应该返回福克斯新闻( Foxs News )中关于狩猎的故事,同时,fox hunting news 应该返回关于猎狐的故事
举例:西红柿&番茄、芝士 & 奶酪
分页原理
Elasticsearch 接受 from 和 size 参数:
size
显示应该返回的结果数量,默认是 10
from
显示应该跳过的初始结果数量,默认是 0
考虑到分页过深以及一次请求太多结果的情况,结果集在返回之前先进行排序。 但请记住一个请求经常跨越多个分片,每个分片都产生自己的排序结果,这些结果需要进行集中排序以保证整体顺序是正确的
注意:谨慎使用深度分页
理解为什么深度分页是有问题的,我们可以假设在一个有 5 个主分片的索引中搜索。 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
现在假设我们请求第 1000 页–结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。 然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
可以看到,在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是 web 搜索引擎对任何查询都不要返回超过 1000 个结果的原因
elasticsearch默认限制最多分页10000条数据,可以用index.max_result_window参数覆盖配置
