背景
之前开发的分布式唯一id比较简陋。这段时间重新设计优化,变成一个独立的项目X-UID。这里记录下设计优化的一些东西
基本算法还是基于snowflake。因为需求就是要一个long型数字,snowflake算法简单高效。
snowflake简单介绍
算法生成的id结构图:
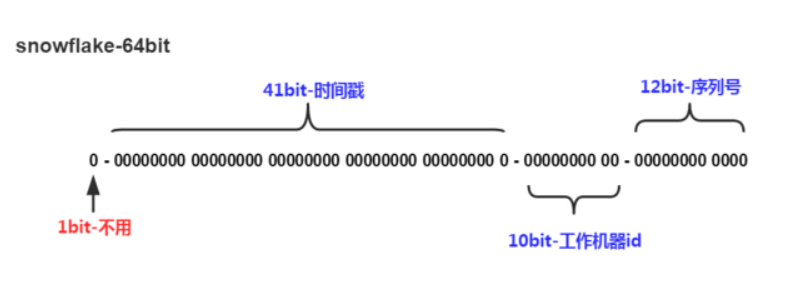
说明:
- 1-bit:符号位,一般不设置,默认为0
- 41-bit:时间戳,大约能用69年
- 10-bit:工作机器id,最大支持1024个workerId
- 12-bit:序列号,毫秒内的自增序列。这也决定了其QPS的上限为400w/s这个数量级
核心代码如下(重点关注nextId()方法):
|
|
snowflake的优点
- 性能高,算法简单高效
- 生成的id趋势递增,不会像单调递增会被竞争对手预测量级
- 无依赖,没有依赖第三方包,更稳定
snowflake的缺点
无法处理时间回拨:一旦发生时间回拨(特别是闰秒的时候),服务不可用或者可能生成重复的id(个人觉得这个最为致命)
以下摘自百度百科:
闰秒,是指为保持协调世界时接近于世界时时刻,由国际计量局统一规定在年底或年中(也可能在季末)对协调世界时增加或减少1秒的调整。
关于闰秒,推荐阅读:传说门
作为一个如此基础的服务,稳定性特别的重要!
瞬时流量高峰,响应时间波动较大。因为生成id的方法整个处于锁的保护下,所有线程串行执行,遇到瞬时大流量,响应时间波动较大
- 功能相对单一。只有一个生成趋势递增id的方法
X-UID的改进优化
解决时间回拨
2个策略:
- 假如回拨的时间毫秒数小于15毫秒(可配置),则等待当前时间赶上lastTimestamp
- 否则,更换一个更大的workerId – 这里就必须有一个集中式的workerId管理了,比如zookeeper
策略存在的问题:
还存在理论上的id重复问题,例如以下执行序列:
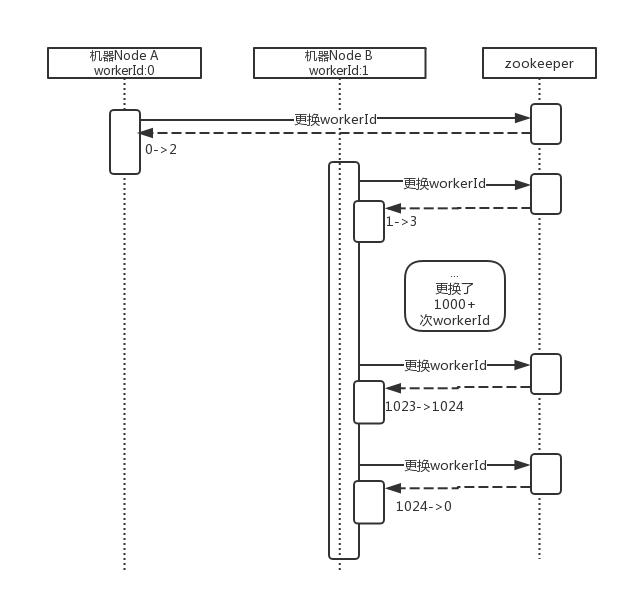
当连续遇到时间回拨,workerId耗尽时,我们选择从0开始寻找一个目前没有在使用的workerId,例如0.这时候,workerId是从大变成了小。如果同时当前机器的时间戳仍然小于使用0这个workerId生成的id使用的时间戳(基本不可能发生),那生成的id将会重复。目前没有一个比较好的解决方案,不过我们对此还是采用了一种柔性处理,这个下面讲
提高响应时间稳定性
其实大部分情况不会有这个量级。纯当挑战下,能否进一步提高性能。
首先就是对原方法的批量改造,即允许一次性生成指定数量的id,核心代码如下:
|
|
之后的关键就是,如何提升性能来应对瞬时大并发。核心思想就是缓存,缓存部分流量低峰或者是平稳期被浪费的id。例如当某个毫秒时刻只有2个生成id的请求,相当于这一毫秒被浪费了4094个id.这部分id完全可以缓存起来应对瞬时大并发。
如下3级缓存架构:
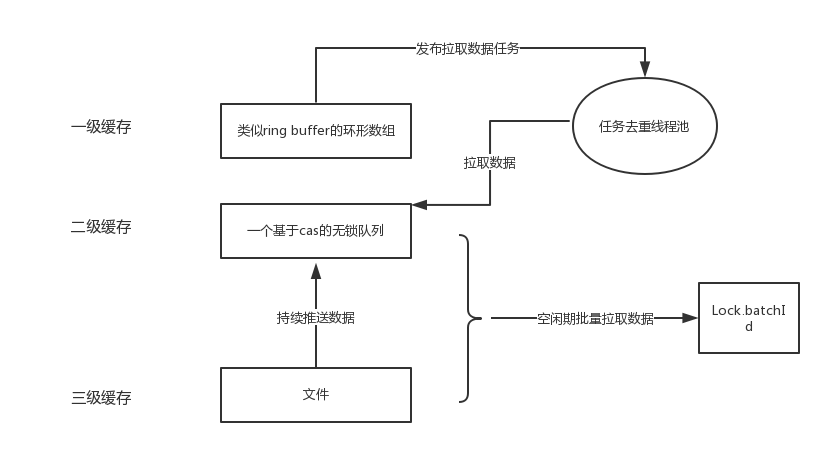
1级缓存是个数组,并发取数据,取空后发布异步任务去2级缓存拉取数据;2级缓存是个阻塞队列,3级缓存其实是文件,会有个线程不断在空闲期调用批量生成id的方法来填充2&3级缓存。并且有另外一个线程不断读取数据推送到2级缓存
1级缓存结构
结构图如下:
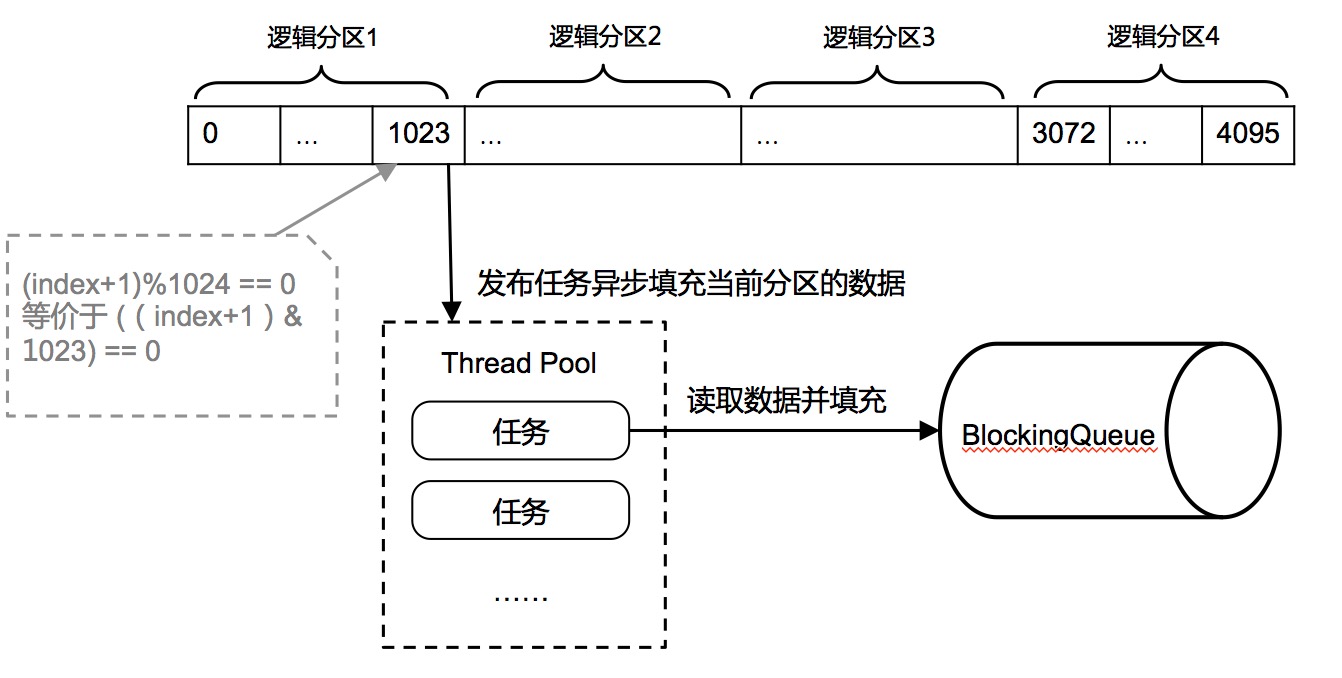
说明:
1级缓存是一个环形数组,默认长度为4096,每个数组槽位采用缓存行填充,避免伪共享(伪共享请参考:传送门)。如何做到环形,就是利用cas让数组下标原子的在0~4095之间循环变动即可
数据填充方式:不是每次被取走就马上填充。而是逻辑上的分为4个分区,也就是每个分区1024个id.当整个分区的id被取走后才发布id填充异步任务。这样有2个好处,减少数组的竞争和批量填充,效率更高。那如何判断这个分区被取空了呢?就是使用
(index+1)&1023==0逻辑与操作代替相对昂贵的取模操作处理异步拉取任务的线程池做过特定优化:会对任务去重。当同一时刻进来4096*2的id请求时,将会发布8个分区填充的任务,而事实上有一半的任务是重复的(填充同一个分区),浪费id,无谓的加重竞争,所以会对任务去重
拉取任务会先尝试(poll()方法)去阻塞队列里获取数据,如果阻塞队列为空,则调用加锁的批量生成id方法生成
2&3级缓存结构
结构图如下:
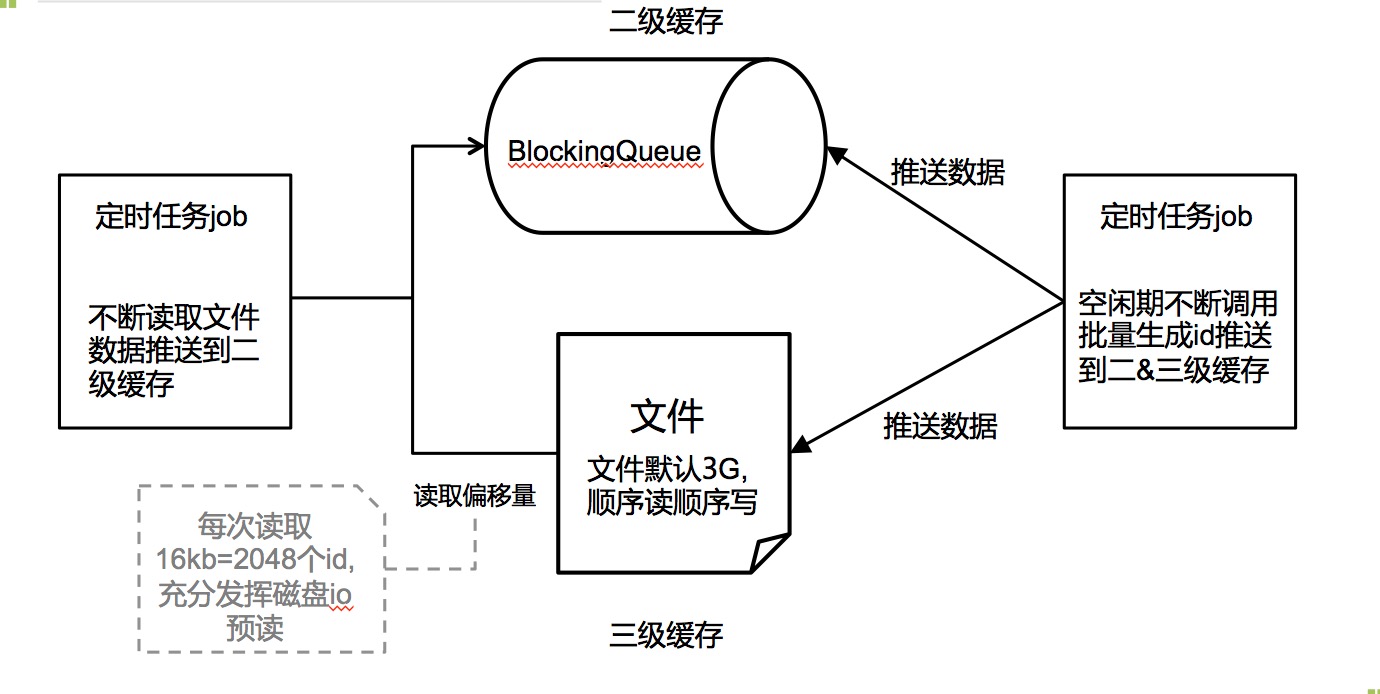
说明:
3级缓存是文件,默认大小3G≈4亿个id.文件顺序读顺序写,系统维护一个读偏移量,每次读取16kb=2048个id的数据量,充分利用磁盘io的预读。数据读完不删除,只有到数据全部读完的时候才会删除整个文件,重新生成一个新的空白文件
有一个定时任务线程,在空闲期不断的调用加锁的批量生成id的方法,把数据推送到2&3级缓存
还有一个定时任务线程,不断的读取文件的id推送到2级缓存阻塞队列
一些说明
有了1级环形数组缓存,为何还有2级缓存?
因为1级数组缓存使用了缓存行填充,其实浪费了将近7/8的内存空间,给其分配的空间不宜过大。二级缓存是个阻塞队列,存的是原始的Long型,内存空间利用率高
而且1级缓存的数据其实是采用主动拉的模式,不能很好的利用生成id方法的空闲期
只使用2级缓存,不用1级缓存,怎么样?
效率没有2着结合的高。首先1级缓存的并发竞争点是对一个int型的数组下标的cas操作,比较的短平快。而阻塞队列竞争是在锁的保护下的,效率相对更低
不使用3级文件缓存可以吗?
不使用文件缓存将失去一些HA(高可用方面的保障)。比如文件可以保存更多的id数据,保障了应对更长时间的大并发大流量。其次,之前说的对时间回拨的柔性处理,其实是利用的文件缓存。因为workerId相对属于有限资源(只有1024个),不到万不得已,不能轻易更换。所以,当发现需要更换workerId(或者更换的workerId比当前小)的时候,我们优先读取文件缓存的id
并且当机器意外重启的时候,文件中的id能保证一段时间的高并发流量的使用
如何判定是否处于空闲期?
判定当前等待锁的线程数。默认等待的线程数大于2(可配置,并且会结合可用的cpu核数综合判定)即认为是繁忙的。
数据对比
电脑配置:MacBook Pro,i5-4核,16G
性能测试使用JMH
吞吐量:
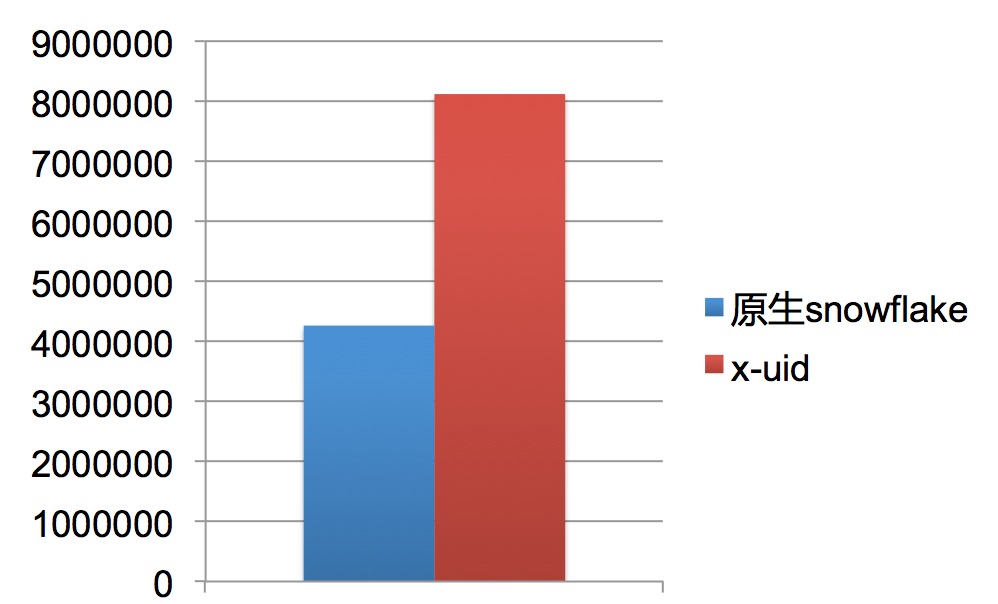
x-uid取的是最低值800w+,正常情况能跑到1200w+.提升了1倍多
思考
这些优化其实就2个人花了2天的时间做的,有些设计还比较混乱,后面会重新整理设计一版。还有一些优化的想法暂时没有实践。比如
- 设计一个更适合这个应用场景(单消费者多生产者)的队列
- 对于从1级缓存获取id的线程分组。因为目前最大竞争点应该是cas1级缓存的数组下标。cas操作有个问题就是大并发下可能造成线程饥饿。考虑对线程hash分组到不同的分区来进一步分散cas热点
- 目前弱依赖了zookeeper,就启动的时候去zk获取workerId,会写入到本地文件。然后更换workerId的时候需要zk。后续考虑自己设计开发一个轻量级的注册中心来做这个事情
- 其他。。。
先完成,再完美
还有就是一个snowflake无法保证的场景,就是需要全局严格的趋势递增(一般是mq的顺序消息排序),snowflake其实是做不到的,它毫秒内无法保证这点。而X-UID只要调用批量生成id,在同一台拉取足够数量的顺序消息id是能严格保证这点的
